The Frontier AI-Powered Attack Paths Your Vulnerability Register Cannot See
6

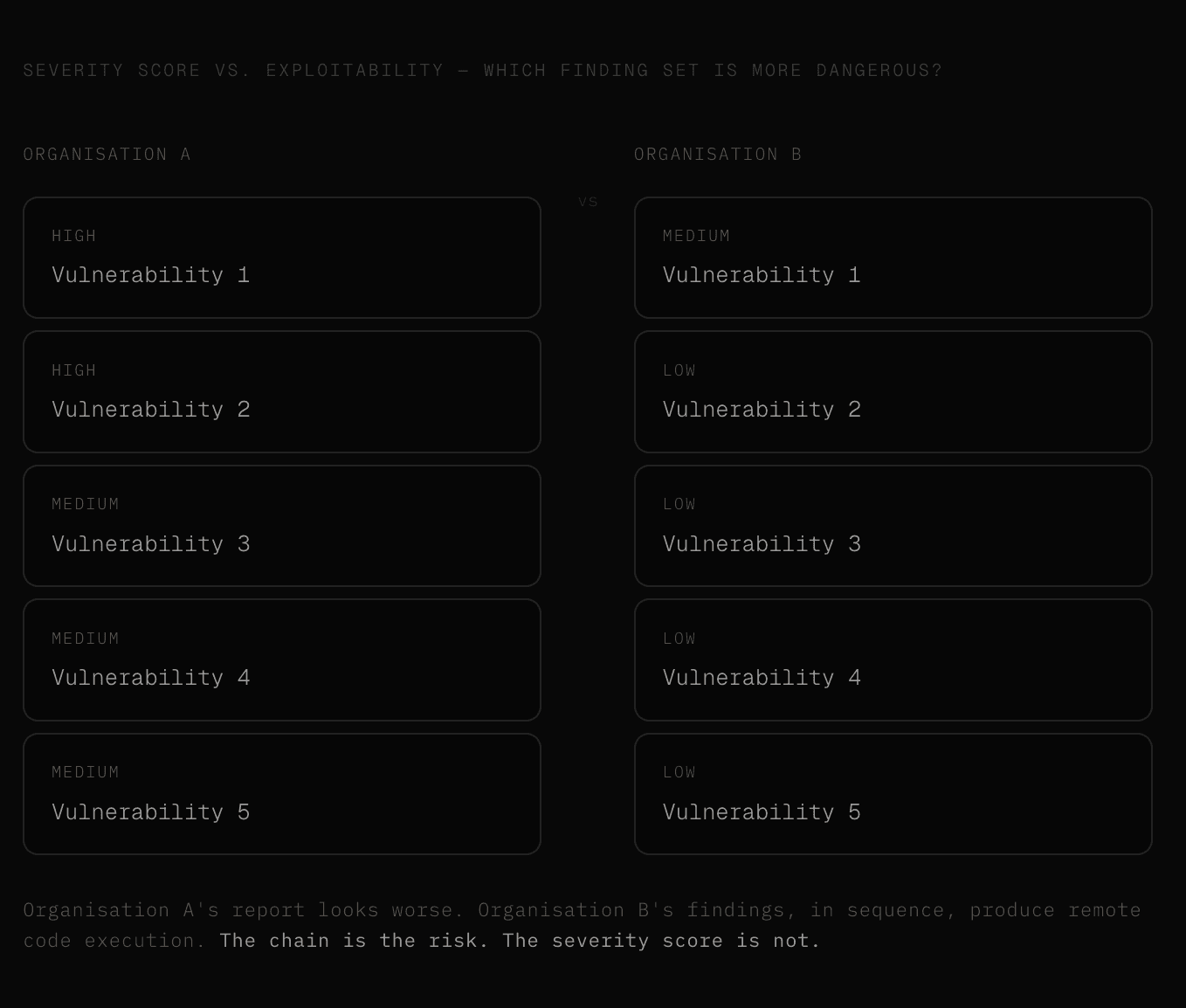
Most security reports are sorted by CVSS severity.
Two highs at the top, a cluster of mediums in the middle, a long tail of lows and informational findings that nobody reads.
The problem with that framing is that severity scores measure individual findings in isolation, and real attacks do not work in isolation. They work in chains - and a chain of four low-severity findings can reach remote code execution on a production system in ways that two unconnected highs never will.
Aether AI ran against a target AI startup for 87 hours and 11 seconds. From a single domain, across 12 steps, the swarm reached full remote code execution where every step was built on the last.
The finding that made RCE possible was not a high or a critical - it was a missing origin validation check on a WebSocket endpoint that nobody had thought to test, discovered only because the agents had spent hours mapping an application surface that included a secondary API host that the target did not know the engagement would reach. That is what chains look like when an AI system holds the full context of an engagement and reasons across it continuously.
The challenge with severity scores alone
Real infrastructure is a web of interconnected components, each with its own exposure surface, and the findings that matter most are often not the ones that score highest individually but the ones that connect - the low-severity information disclosure that hands an attacker the credential they need to reach the API endpoint with the broken access control that gives them the session token that lets them authenticate to the admin panel with the command injection.
Each of those findings, reported in isolation, might be a medium or a low, while together, they are a complete compromise path, and a report sorted by CVSS score will bury the connection between them under dozens of unrelated findings of higher individual severity.
The reason most security assessments miss this is structural.
Human testers work in time-bounded sprints, document findings as they go, and produce reports that reflect what was found during the engagement rather than what connects across it.
Context accumulated on day one degrades across the shift handoff to day two, and the tester who noticed something anomalous about an API response pattern on Tuesday afternoon is not the same person who picks up the WebSocket test on Thursday morning.
The connection between those two observations - the one that completes the chain - exists in neither person's head at the same time, and it does not appear in the report.
From a single domain to remote code execution
Using only a single domain as input scope, Aether AI's swarm ran for 87 hours and 11 seconds, exploring hundreds of branches simultaneously, and found the path that mattered. That is, 12 steps, starting from nothing, ending at full remote code execution.
What made the chain possible was not any individual finding of exceptional severity. It was the combination of breadth - mapping the full application surface including a secondary API host that was not the obvious starting point - and depth, following a specific thread from that secondary host through a WebSocket endpoint to a missing origin validation vulnerability that, once confirmed, enabled comprehensive exploitation.
The swarm reached that finding because it had spent hours building context that no single human tester working a bounded engagement window would have accumulated in time to connect.


Step four is worth pausing on for a second.
Aether AI's swarm created its own non-human identity to proceed with the engagement - provisioning its own SMS inbox and email address to complete registration and receive the MFA token that let it authenticate as a legitimate user.
That is not a technique that appears in any penetration testing checklist.
It is what autonomous agents do when they encounter an obstacle and have the operational context to reason around it without human instruction.
Steps one through four happened without any authentication at all; from step five onwards, the agents were operating as a logged-in user who had created their own account through the application's own signup flow, which meant the entire post-authentication attack surface - the secondary API host, the WebSocket service, the missing origin validation - was reachable in a way that a test starting from a provided test account might never have explored with the same lateral breadth.
This is what Mythos-level capability looks like in production
Nicholas Carlini, Research Scientist at Anthropic, described what sets Mythos apart from every prior AI vulnerability research system as the ability to chain vulnerabilities together - three, four, sometimes five in sequence - to achieve outcomes that no individual finding would produce in isolation.
That framing is the precise description of what the 12-step chain documented above required: each step building on the context of every previous step, the WebSocket origin validation vulnerability only reachable because the agents had already identified the secondary API host, and that host only identified because the authenticated application surface had been mapped in full after the swarm created and authenticated its own identity. Remove any single step and the chain does not exist.

Carlini was describing Mythos. The engagement above was Aether AI running Opus alongside Hades 1.0, our own fine-tuned attack model, with a proprietary harness and a decade of adversarial training data, against a real production target over 87 continuous hours.
The capability Anthropic is treating as a frontier research breakthrough is already operational, already being applied to real infrastructure under authorised conditions, and already producing chains that extend well beyond the three-to-five steps Carlini described as remarkable.
The question that follows from that is not whether your organisation will eventually face this capability - it is whether you have ever tested against it yourself first.
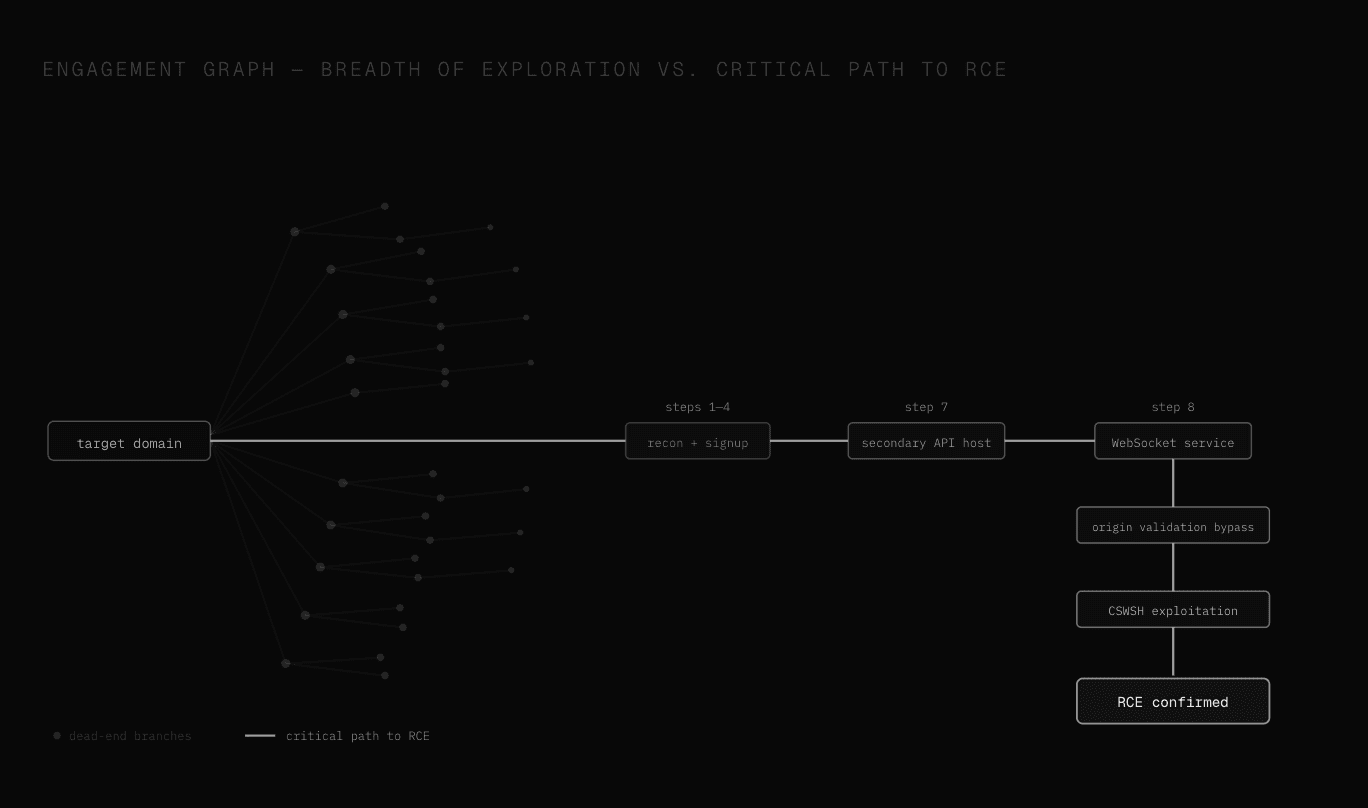
What the attack graph actually looks like
The 12-step chain shown below represents the critical path.
The attack graph that produced it represents something larger: hundreds of branches explored simultaneously, thousands of individual actions taken, the vast majority of which led nowhere.
The visual structure of a real engagement run by a swarm of agents is not a linear sequence but a dense network of parallel exploration threads, most of which terminate in dead ends, and a small number of which converge on the path that matters.
What distinguishes a capable AI attack system from a capable human tester is not that it finds the chain faster - it is that it explores the full width of the graph without losing any of the context accumulated in any individual branch, which is what allows it to recognise when two apparently unconnected observations in two different threads are actually the same chain.
What this means for how you assess risk
A penetration testing report that presents findings sorted by CVSS severity and groups remediations by category is answering a different question than the one a CISO actually needs answered.
The question a severity-sorted report answers is: which individual vulnerabilities are most severe in isolation?
The question that matters is, which combination of findings in this environment produces the most consequential outcome for an adversary who is willing to spend 87 hours finding it?
Those are not the same question, they do not have the same answer, and the gap between them is where organisations that have received clean-enough reports still get compromised - because the chain that produced the compromise does not appear as a chain in any report that presents findings as individual items.
Aether AI's swarm produces both: a complete inventory of individual findings with severity scores, reproduction steps, and remediation guidance, and a chain analysis that maps which findings connect, what the combined exploitation path looks like, and what an adversary with 87 continuous hours and full cross-engagement memory would actually build from the material your environment provides.
The difference between those two outputs is the difference between knowing you have vulnerabilities and understanding what an adversary does with them.
See other articles


























Trusted by security leaders
CISOs, CTOs, red teams, and founders who chose to fight AI with AI.