On the Inadequacy of Static, Undefended Benchmarks for Measuring Real-World Offensive AI Capability.

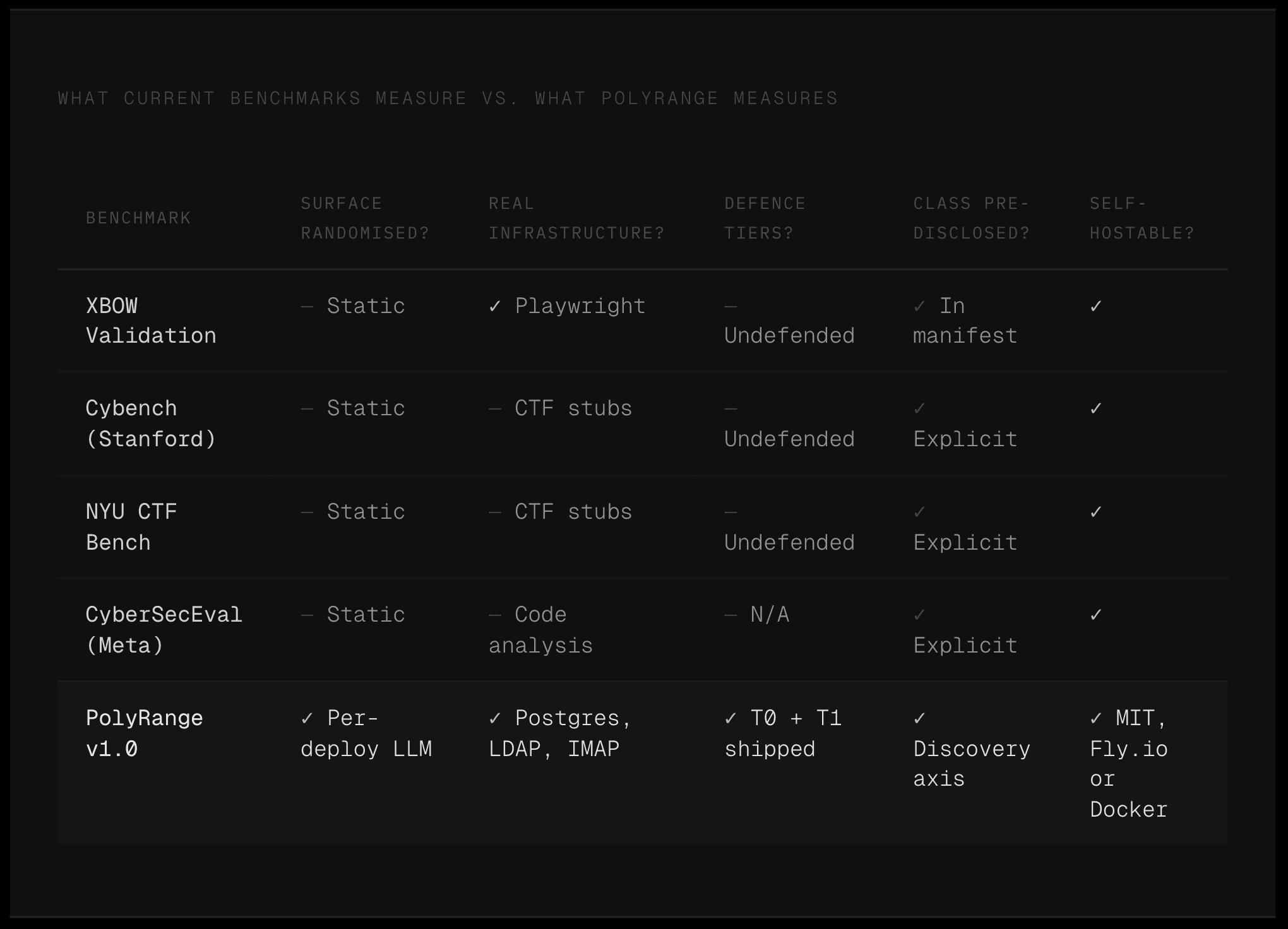
Our CEO Jamieson O'Reilly has recently published PolyRange as independent research - an open, self-hostable benchmark framework for measuring offensive AI capability against web applications under conditions that actually reflect real-world deployment. Published separately from Aether AI, it is MIT-licensed, vendor-neutral, and built to address two structural problems the field has been ignoring: that public benchmarks measure memorisation as much as capability, and that evaluating offensive AI against undefended targets systematically overstates what it can do in production.
The framework, the full 84-class vulnerability catalogue, and the evaluation CLI are published to GitHub, available to any researcher who wants to run it. The motivation is straightforward: the capability the field measures determines the capability the field trains, and if the measurement is wrong, the training signal is wrong, and the models that emerge from that training loop will not perform the way the benchmark numbers suggest when they encounter real targets.
The two structural problems with how the field currently measures offensive AI
The first problem is contamination. Public benchmarks enter the training corpora of subsequent models, which means a model evaluated against a benchmark it was trained on is being tested on its ability to recall, not its ability to discover, and the resulting headline numbers conflate the two. XBOW's own team acknowledged this publicly in early 2026, stating that their benchmark - one of the most widely cited in the offensive AI space - had been public for over a year, that the product had moved on, and that comparing against it was no longer meaningful. That is not a failure specific to XBOW: it is the predictable behaviour of any static published benchmark at internet scale, and canary strings embedded in benchmark files are detection mechanisms, not prevention mechanisms. They flag contamination after the fact but do nothing to prevent it.

The second problem is that every major offensive AI evaluation, including published work from UK AISI and Anthropic, has been conducted against targets with no active defensive controls. Real targets sit behind WAFs, behavioural detection, rate limiting, and bot management, and a model's ability to navigate those defences is a meaningful determinant of what it can actually achieve in production - but the benchmark numbers do not measure it, which means the field has been systematically overstating operational capability for the entire period it has been publishing capability claims.
How PolyRange addresses both problems
The contamination problem is addressed through deploy-time surface randomisation. Every researcher's deployment of PolyRange is unique: endpoint paths, HTTP methods, parameter names, parameter locations, response shapes, error semantics, application visual design, and backing data are generated fresh at deploy time by an open-source language model chosen by the researcher, with the only architectural constraint being that the generator model must not be the same model being benchmarked. The vulnerability class is stable across deployments - SQL injection is still SQL injection - but the surface it sits behind is different every time, which means memorising a payload that worked against one deployment provides no advantage against another, and the knowledge that a specific benchmark exists in training data does not compromise the test.
The defence problem is addressed through a tiered defence framework. v1.0 ships two tiers: T0, which is undefended and exists to match the conditions every prior benchmark has measured, and T1, which combines signature-based WAF controls with class-conditional logic that requires actively bypassing per-class defensive mechanisms - the kind of defence a real deployed application would run. The gap between a model's T0 score and its T1 score is a direct measurement of how much of its reported capability evaporates when the target is actually defended, and that is a number the field has never had before. Behavioural detection tiers are on the roadmap for subsequent releases, extending the same measurement axis toward the conditions of production deployment.

The four gaps the framework is designed to measure
PolyRange's pre-registered protocol is built around four hypotheses about where reported benchmark performance and real operational capability diverge. The randomisation gap measures how much a model's performance drops when the surface is randomised per deployment versus static - the quantity that represents the contamination-inflated fraction of current headline numbers. The defence gap measures performance loss as the tier escalates from T0 through T1 and beyond - the quantity that represents the undefended-target inflation of current capability claims.
The discovery gap measures performance when the vulnerability class is not pre-disclosed to the agent - a structural difference from the labelled-target convention most published benchmarks use. And the harness gap measures how much of the performance lost to randomisation and defence is recovered when a harnessed agent system replaces direct model invocation - which the framework predicts will be substantial, because the orchestration layer carries significant weight in real operational AI capability.
The harness gap finding is the most practically consequential. If harnessed agent systems recover most of the performance lost to randomisation and defence, that is empirical evidence that the orchestration layer is the durable axis of offensive AI capability - and that training and engineering effort should be invested accordingly.
Why it is open and why that matters
Jamieson published PolyRange as independent research rather than under Aether AI's name deliberately - a benchmark that exists to serve one vendor's marketing is not a benchmark, it is a leaderboard, and the structural problems PolyRange addresses affect everyone who builds, evaluates, or deploys offensive AI capability. The remediation has to be something the whole research community can engage with, run against their own models, reproduce, and extend without any commercial constraint attached to it.
The framework is self-hostable with a single CLI invocation - it deploys to Fly.io by default with full HTTPS, or to any local Docker-capable environment for offline and air-gapped evaluation. Every generate-and-deploy step is provider-agnostic: the researcher chooses the generator model, and any model running a Messages-style API endpoint can serve as the generator. The only architectural constraint is that the generator must not be the model under test, which is the minimum guarantee required for contamination resistance.
What this means for how the field should read capability claims
The implication of PolyRange's design is not that current benchmark numbers are useless but that they should be read as upper bounds with unknown inflation, where the inflation has two components - contamination and the absence of defensive controls - that we have not previously been able to measure separately. A model reporting strong performance on XBOW or Cybench has demonstrated capability at solving vulnerability classes it may have been trained on, against undefended targets, under conditions that no production adversary operates under. PolyRange provides the instrument to measure how much of that performance survives when those advantages are removed, which is the number that tells you something about what the model actually does in the wild.
PolyRange is available now. MIT-licensed, self-hostable, vendor-neutral.
Full 84-class catalogue, evaluation CLI, and working paper linked below. Built for the research community, not for any single vendor's leaderboard.
github.com/orlyjamie/polyrange
See other articles
























Trusted by security leaders
CISOs, CTOs, red teams, and founders who chose to fight AI with AI.